
A few weeks ago, Databricks released DBRX, which they have dubbed as an open general-purpose LLM. DBRX utilizes a Mixture of Experts architecture, an architecture which is becoming a gold standard across all new LLMs. In fact, Databricks has gone to the extent of contrasting DBRX with dense models therefore further refining the gold standard to 24 carats as Sparse Mixture of Experts.
Databricks asserts that DBRX not only doubles the inference speed compared to models like LLaMA2-70B but also surpasses them in quality. Furthermore, Databricks highlights that DBRX excels as a coding model, significantly outperforming specialized models like CodeLLaMA-70B in programming tasks, showcasing its superior capabilities and setting a new benchmark in the field.
Metering the Parameters
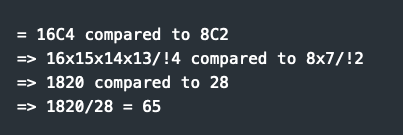
DBRX showcases an optimal utilization of its architecture through its Sparse Mixture of Experts (sMoE) configuration, holding a total of 132 million parameters with only 36 million actively engaged at any given time by activating just 4 out of its 16 experts. This provides 65x more combinations than 2 out of 4 Mo
In addition, this efficient activation strategy minimizes parameter overlap, enhancing the model’s performance and efficiency. Without overlap, the active parameter count could reach 144 million.
In contrast, Mixtral, which employs 8 experts, activates 13 million parameters from a total of 47 million. If there were no overlap in Mixtral, it would potentially use up to 52 million parameters. This comparison highlights DBRX's superior efficiency in parameter utilization and expert management, despite having twice as many experts, resulting in less duplication compared to Mixtral.
Training Stack
Revisiting Databricks' Training Stack, Databricks is set to revolutionize model building by offering their well-developed training stack to customers, enabling them to construct models from the ground up. This could fundamentally change the approach to pre-training, effectively serving as a detailed guide for efficient and effective model training.
While the promise of such a resource is enticing, it remains skeptical until we have the opportunity to evaluate its real-world utility. A considerable hurdle for users will be securing access to the vast amounts of text and code data—approximately 12 trillion tokens—necessary for meaningful training. If Databricks only provides a pre-trained model, then the playbook's value might be limited primarily to educational purposes, which seems likely. The challenge for customers doesn't lie in just obtaining a training guide but in accessing enough quality data to utilize such a guide effectively.
Following is Databricks statement on this data:
DBRX was pretrained on 12T tokens of carefully curated data and a maximum context length of 32k tokens. We estimate that this data is at least 2x better token-for-token than the data we used to pretrain the MPT family of models. This new dataset was developed using the full suite of Databricks tools, including Apache Spark™ and Databricks notebooks for data processing, Unity Catalog for data management and governance, and MLflow for experiment tracking. We used curriculum learning for pretraining, changing the data mix during training in ways we found to substantially improve model quality.
It seems there's quite a bit to consider here. Instead of building models from scratch, we anticipate that enterprises will adopt a more efficient approach. They'll likely start with DBRX-base and focus on retraining only the specific areas that require significant enhancements. Importantly, they have the option to refine the model through supervised fine-tuning, particularly using features like DBRX instruct, to tailor the model more closely to their specific needs.
Conclusion
Two trends are becoming clear. First, every enterprise is looking to develop its own customized LLM. Second, the interaction between an enterprise’s data and LLM weights is becoming increasingly influential. Positioned uniquely due to their expertise with Spark and related technologies, Databricks is well-placed to capitalize on these developments.
As a legacy Gold Partner with Databricks, InfoObjects Inc. is thrilled to once again be converging down the path of innovation. We're now focused on fine-tuning Open Large Language Models and enriching these models leveraging Retrieval-Augmented Generation .
